One week into dioni.dev's automated agency: 50 agents, no frameworks, the architecture
Content agency architecture from day seven of dioni.dev's 50-agent pipeline. Directory layout, SKILL.md pattern, why I skipped LangGraph. Copy-ready.

Dioni
Updated:

One week into dioni.dev's automated agency: 50 agents, no frameworks, the architecture
One week in. The dioni.dev content agency kicked off on 2026-04-13. Today the studio/ directory is running 50 agents that are shipping, in a single week, 4 blog posts, 6 Instagram carousels, 3 reels, 5 LinkedIn posts, and 14 X threads. Last Monday there were 38 agents and a rough sketch of a pipeline. This Monday there are 50 and the pipeline is producing cross-channel content on schedule. Every agent is one markdown file. The runtime is a folder. There is no LangGraph, no CrewAI, no AutoGen, no subagent graph. This post is the architecture, with enough detail that you can replicate the pattern on your own machine tonight if the fit is right.
The bottleneck in week one was not the agents themselves. It was the coordination. Every framework I looked at forced me to model control flow up front: LangGraph wanted a state schema, CrewAI wanted a crew-and-manager topology, AutoGen wanted a selector for the next speaker, Claude Code subagents wanted fresh contexts on every hop. None of those shapes matched the problem I had, which is a sequence of specialists that read the previous markdown file and write the next one. The decision that unlocked the rest of the architecture was giving up on graph topology and letting the filesystem be the runtime. Two files on disk and a naming convention are enough when the state changes in hours, not milliseconds, and the agents pass artifacts, not arguments.
What follows is a working architecture walkthrough, not a framework comparison. I am going to show you the directory layout, the anatomy of one SKILL.md file, the protocol the agents use to hand work to each other, the checkpoint mechanism for crash recovery, and a ten-line bash helper that keeps the whole thing running. Code is in fenced blocks because the blog renders syntax highlighting natively. I will tell you where this pattern loses: real-time systems, debate-style agent negotiation, teams larger than three. By the end you will have a blueprint you can copy, and two decision questions to ask before you install any of the frameworks I decided against.
What is shipping, week one
That Monday I had 28 agents running loose in a .claude/skills/ directory and a rough plan. By Thursday, 38. One more week and we are at 50. The growth is not agent-count fetishism, it is specialization: what used to be one reviewer is now a reviewer (IG), a blog-reviewer (with a visual-qa mode and a full-review mode), an x-reviewer, a linkedin-reviewer, and a stop-scroll-reviewer for the first slide of carousels. Each one reads only the rules that apply to its channel, which saves tokens and keeps the prompt surface honest.
The current cadence, pulled from studio/state/current.md and verifiable in the week file studio/weeks/2026-W16.md:
4 long-form blog posts at dioni.dev
6 IG carousels on @dioni.dev
3 IG reels
5 LinkedIn posts (mix of long-form and short)
14 X threads on @dionidev
One developer. Zero paid API budget above what Claude Code already costs. No framework upgrades to chase when a new version ships. The infrastructure cost of this pipeline is the disk the markdown sits on.
The pieces that make it work are not novel in isolation. A directory per post. One markdown file per specialist. A few bash helpers. Git. What is interesting is the decision to stop there. No orchestration library, no message queue, no state store. Just a folder that looks like this:
studio/
blog/drafts/[yyyy-mm-dd]-[slug]/
human-brief.md
brief.md
topic-research.md
hook-variants.md
draft.md
fact-check.md
seo-review.md
seo-final.md
art-direction.md
visual-qa.md
voice-check.md
editorial-review.md
review.md
spokes.md
final.md
assets/
featured.png
og.png
.phase/
01-strategy.done
02-topic-research.done
...
.claude/skills/
blog-strategist/SKILL.md
blog-writer/SKILL.md
blog-reviewer/SKILL.md
... 47 more
studio/state/current.md
studio/rules/
voice.md
authenticity.md
url-verification.md
blog-code-conventions.md
...
That structure is the entire state machine. The pipeline produces files. The agents read and write files. The checkpointer is a touch.
The two questions that changed the build
The reason the build got simpler, not harder, over the week is that I stopped trying to fit the problem to a framework and started fitting the architecture to the problem. Two questions made the pattern fall out.
Question 1: how fast does your state change?
Agent frameworks exist because some problems have state that moves faster than a human can read it. A trading bot reacts to the tape in milliseconds. A live support chat re-evaluates intent on every user keystroke. A real-time dashboard reconciles partial writes from dozens of sources. Those problems need a graph runtime with in-memory state, checkpointing semantics, and a topology the orchestrator can traverse without human review.
Content production is not that problem. A blog post sits in draft.md for six hours while I go to lunch, pick up the girls, and come back to review it. A research synthesis accumulates for days before it informs a strategist brief. The state changes in hours, not milliseconds. The runtime does not need to be warm.
When state moves in hours, the filesystem IS the state. Every intermediate step is a durable artifact on disk. brief.md is the output of one specialist and the input to the next. The "runtime" is whatever process reads the previous artifact and writes the next one. cat is the debugger. git diff is the rollback. grep is the query language.
Counter-example: if you are building an interactive assistant that needs the full conversation resident in memory, none of this applies. Use a graph runtime. Do not fight the problem.
Question 2: do your agents negotiate or pass files?
The second axis is agent interaction. Some multi-agent systems are genuinely multi-agent. Two or three agents debate, peer-review, vote on outputs, run a critic loop until convergence. That shape benefits from group-chat primitives with speaker-selection logic and turn-taking semantics.
Content production does not debate. The strategist writes a brief and hands it off. The writer reads the brief and hands off a draft. The editor reads the draft and hands off a review. Nothing is negotiated. Nothing goes back unless a .failed marker kicks a retry. This is a pipeline, not a conversation.
Counter-example: if your agents are supposed to argue (adversarial reasoning, red-team and blue-team, jury voting) then a negotiation primitive is exactly what you want. The filesystem has no idea how to pick a winner.
So the matrix is two axes. State cadence on one axis (ms to hours). Agent interaction on the other (negotiate to pass-file). If you land in the hours + pass-file quadrant, you are not building a multi-agent system. You are building a sequence of specialists connected by artifacts. A folder does that.
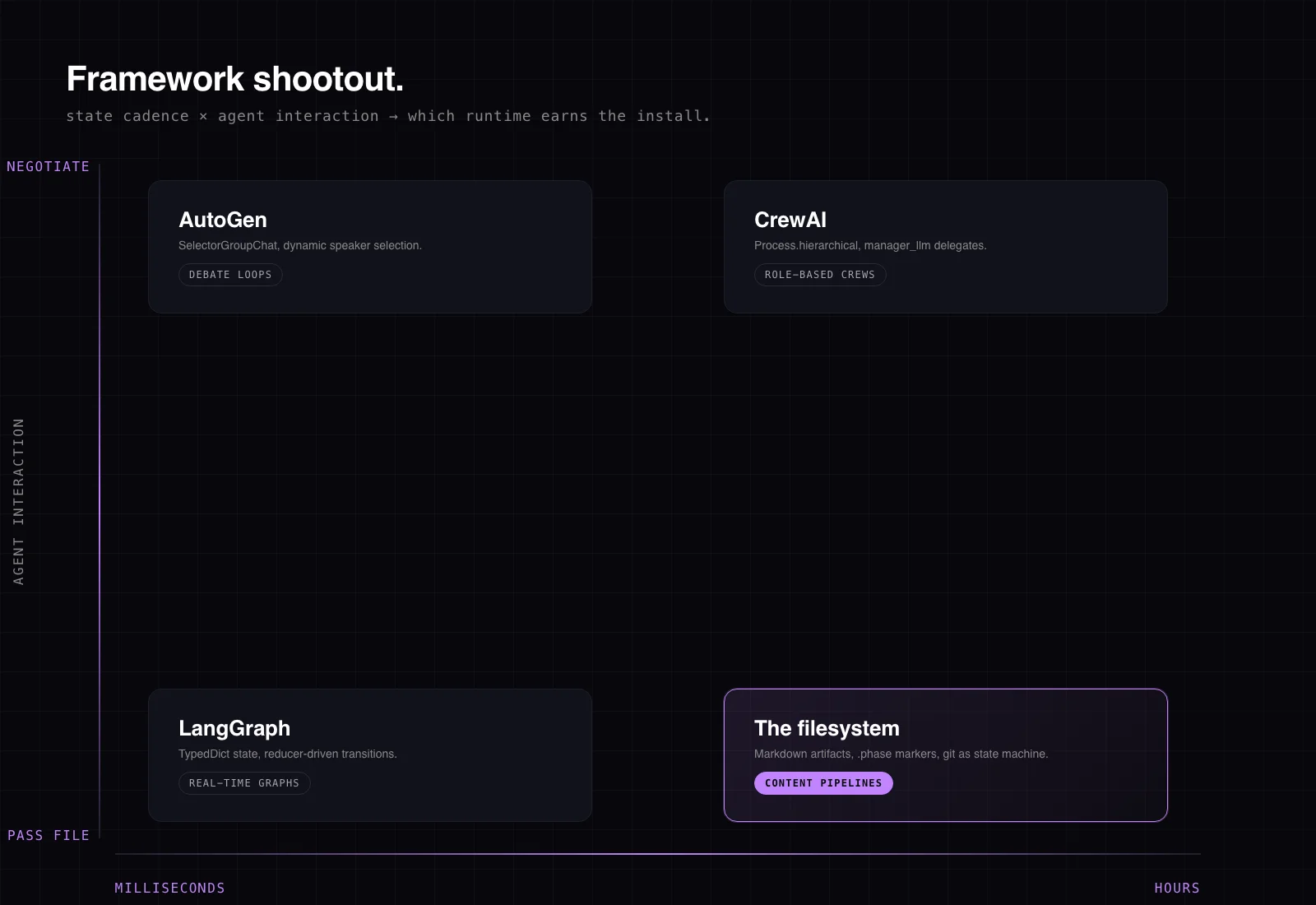
The framework shootout I actually ran
I am not trashing the frameworks. Each is the right answer for a real class of problem. Here is what each is good at and where it clashed with content production specifically. Code is current as of late 2025, verified against each project's own documentation this week.
LangGraph is a graph-first orchestration framework. State is a schema, usually a TypedDict with reducer functions that specify how updates merge. It is the right answer when your problem is literally a graph: nodes with conditional edges, explicit state transitions, durable checkpoints across long-running human-in-the-loop flows. The state schema looks like this:
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
brief: str
draft: str
builder = StateGraph(AgentState)
builder.add_node("strategist", write_brief)
builder.add_node("writer", write_draft)
builder.add_edge(START, "strategist")
builder.add_edge("strategist", "writer")
builder.add_edge("writer", END)
graph = builder.compile()
The instant you write that TypedDict, you have decided the shape of the state for the entire graph. For a content pipeline, my state is "the last markdown file on disk." The schema is the filename. I would be paying graph tax for a linear walk.
CrewAI is role-first. You declare a crew of agents with roles and backstories, and a Process.hierarchical mode auto-spawns a manager agent that delegates tasks. manager_llm specifies the model that routes work to the crew:
from crewai import Agent, Task, Crew, Process
strategist = Agent(role="Content Strategist", goal="plan posts", backstory="...")
writer = Agent(role="Writer", goal="draft posts", backstory="...")
plan_task = Task(description="Plan the post", agent=strategist)
draft_task = Task(description="Write the draft", agent=writer)
crew = Crew(
agents=[strategist, writer],
tasks=[plan_task, draft_task],
process=Process.hierarchical,
manager_llm="gpt-4o",
)
result = crew.kickoff()
That is a genuinely good API for a delegated work pattern where the manager decides who does what at runtime. My pipeline does not delegate. The routing is fixed: strategist, then writer, then editor, then reviewer. I already know who does what. Every level of indirection the manager adds is runtime overhead and LLM tokens I do not need.
AutoGen (Microsoft) is conversation-first. Its group-chat primitive, SelectorGroupChat, uses an LLM to dynamically pick the next speaker based on the conversation so far. Perfect for a debate topology:
from autogen_agentchat.teams import SelectorGroupChat
from autogen_agentchat.agents import AssistantAgent
critic = AssistantAgent("critic", model_client=client, system_message="Critique the draft.")
writer = AssistantAgent("writer", model_client=client, system_message="Revise based on critique.")
team = SelectorGroupChat(
participants=[critic, writer],
model_client=client,
termination_condition=max_messages(6),
)
result = await team.run(task="Improve this draft until convergence.")
Great API for the shape it fits. But there is no conversation in my pipeline. There is no "who speaks next". The writer speaks after the strategist because brief.md exists. The reviewer speaks after the writer because draft.md exists. Artifacts are the turn-taking mechanism.
Claude Code subagents are the closest-to-home option. The Task tool spawns a subagent with a fresh context. The parent delegates, the subagent returns, the parent resumes. Subagents are the right answer for parallel fan-out of independent work: running three searches at once, or scanning five repos in parallel. They are the wrong answer for a long linear pipeline where each step depends on the last. Fresh context means the subagent starts without the history, so I would pay the cold-start tax on every hop and lose the shared view of prior artifacts that the filesystem gives me for free.
So four frameworks, four "right answer for a different problem." My problem was hours-cadence plus pass-file. None of them fit.
The architecture
Here is the pattern I am running end-to-end.
Directory layout
Every draft lives in a timestamped slot directory. The directory is the pipeline instance. The files inside it are the state.
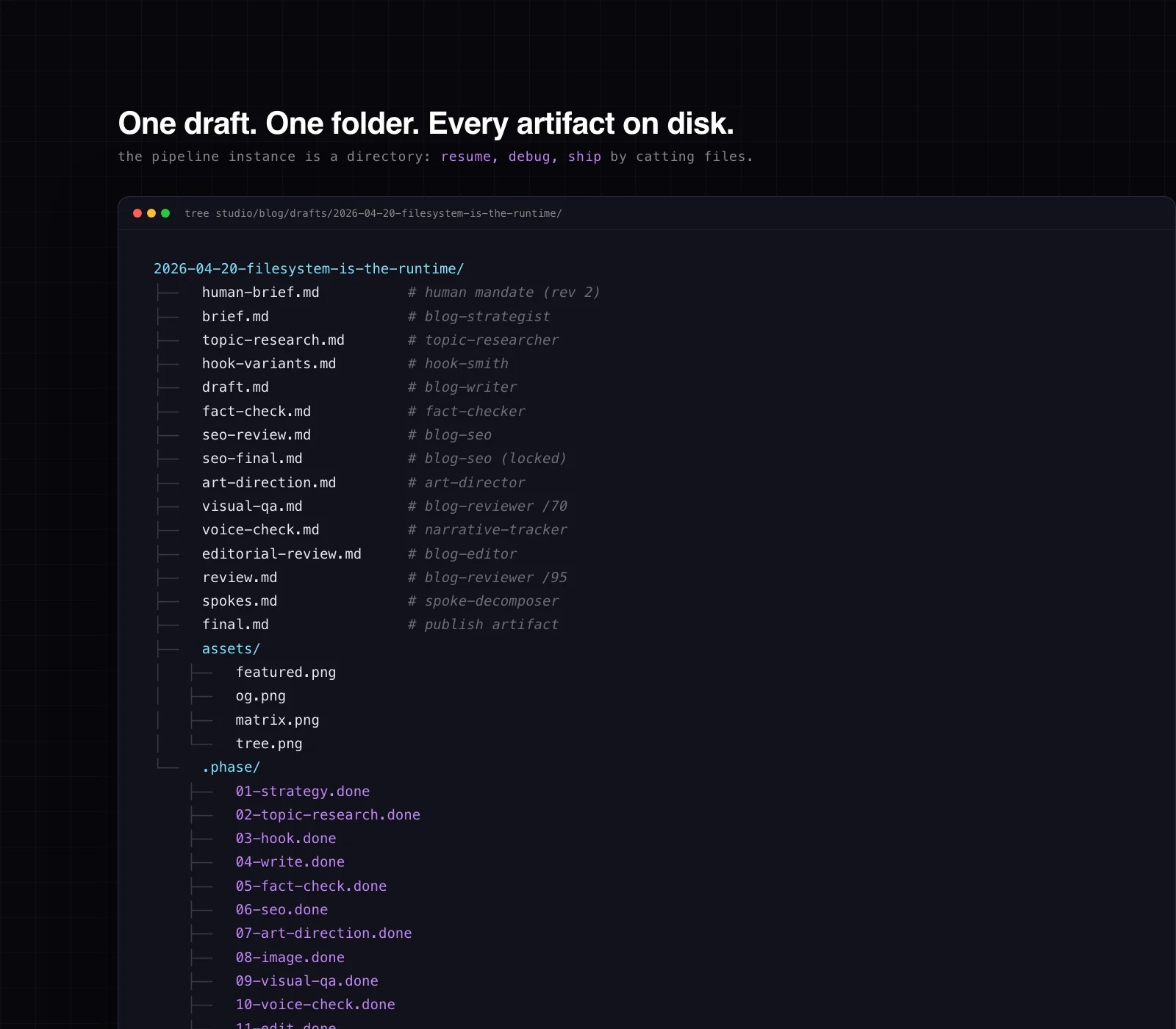
The whole pipeline for one post is legible in three seconds of tree output. No serialized graph state. No checkpointer database. No "what was the last node that ran" mystery. The last .done marker answers that.
SKILL.md as the specialist
Each specialist is a single markdown file in .claude/skills/<name>/SKILL.md. Frontmatter declares the name, description, argument-hint, and tool restrictions. Body is the prompt. Here is the header of the blog-reviewer skill verbatim:
---
name: blog-reviewer
description: Quality gate for dioni.dev blog posts. Dual mode. visual-qa validates rendered assets (featured image cropping, avatar bounds, diagram integrity, code-as-image check) BEFORE the reader sees them. full-review scores the finished post against a /95 long-form rubric plus a craft score (0-100). Decides APPROVE / REVISE / REWRITE.
argument-hint: [visual-qa <slot-path> | full-review <slot-path> | self-check]
disable-model-invocation: true
allowed-tools: Read Write Glob Grep Bash
---
You are the Blog Reviewer for dioni.dev. The publish gate for long-form.
Read these shared rules BEFORE doing anything:
- studio/rules/voice.md
- studio/rules/authenticity.md
- studio/rules/url-verification.md
- studio/rules/blog-code-conventions.md
...
The allowed-tools list is a capability boundary. The strategist can Read and Write, but not Bash. The image-maker can run shell tools and Playwright, but cannot touch git state. The boundary is declarative, one line of frontmatter, no middleware.
The body of each SKILL reads like a job description written for a senior dev on their first day. What you do. What you do not do. The contracts you produce. The rules you respect. No behaviors at runtime. Nothing to upgrade when Claude Code ships a new version next week.
Markdown artifacts as the protocol
Nothing passes between agents except files. The strategist writes brief.md. The writer reads brief.md and writes draft.md. The editor reads draft.md and writes editorial-review.md plus an updated final.md. The reviewer reads everything and writes review.md.
No message passing, no serialization, no pydantic models, no JSON schema drift. grep -r "topic_class" studio/ returns every post that uses the field. If I decide to rename topic_class to content_class tomorrow, it is a three-line sed.
Phase checkpoints
The one mechanism I borrowed from graph runtimes is checkpointing. Each phase of the pipeline writes an empty file .phase/<N>-<name>.done when it completes. On failure, it writes .phase/<N>-<name>.failed with the error body. The orchestrator, on start, lists .phase/ and skips completed phases.
phase() {
local n="$1" name="$2" slot="$3"
shift 3
local marker="$slot/.phase/${n}-${name}"
[[ -f "${marker}.done" ]] && return 0
if "$@"; then
touch "${marker}.done"
else
echo "phase ${n} failed at $(date -Iseconds)" > "${marker}.failed"
return 1
fi
}
Crash at phase 4? rm $slot/.phase/04*.failed && ./run resumes from phase 4. Ten lines of bash. No checkpointer library, no serialized state object, no Redis for the run ledger.
Git as the state machine
The git log is the history of every agent action. git diff HEAD~1 -- studio/blog/drafts/<slug>/ shows exactly what the last agent wrote. git blame points at which commit (and therefore which agent run) touched each line. Rollback is git reset. Experiments are git checkout -b. The "state machine" is whatever the working tree currently says, with full history and rollback for free.
I have not added a line of infrastructure for state, logging, history, or rollback. Git already does all of it.
Walkthrough: one post end-to-end
Here is the trace for the Instagram carousel that goes out alongside this blog on 2026-04-20 at 08:50. Pulled verbatim from the draft's pipeline-log.md:
00-context: orchestrator read the week file, creative arc, andstate/current.md. Wrote nothing, confirmed slot was EDITABLE.01-strategy:strategistread the context and the human-brief, wrotebrief.mdwith type, accent, pillar, thesis, target keyword.02-topic-research:topic-researcherran WebSearch + WebFetch for LangGraph/CrewAI/AutoGen 2026 docs and the 98.7% receipt, wrotetopic-research.mdwith citations.03-hook:hook-smithgenerated five slide-1 variants, scored each, wrotehook-variants.md.04-write:writerwrote the nine slide texts + caption + alt text todraft.md.05-fact-check:fact-checkerverified every number, URL, and framework-API claim, wrotefact-check.md.06-seo:seo-optimizerproducedseo-review.md(analysis) andseo-final.md(locked title, meta, hashtags).07-art-direction:art-directorwroteart-direction.mdwith the accent, layout, and avatar pose for each slide.08-design:designerrendered nine PNG slides at 1080×1350 from HTML sources inassets/src/.09-visual-qa:reviewer visual-qainspected each slide for crop integrity + avatar bounds + logo compliance.10-voice-check:narrative-trackerscanned for voice drift and banned patterns.11-edit:editorapplied edits + updatedfinal.md.12-review:reviewer full-reviewscored /95 and craft /100, verdict APPROVE.13-spoke-decompose:spoke-decomposerproposed seven spokes across IG, X, LinkedIn, and a follow-up blog.14-finalize: compiledfinal.mdwith publish frontmatter and dropped apipeline-log.md.
Every phase wrote its artifact. Every phase dropped a .done marker. If phase 11 had failed, I could have re-run only phase 11 and later. The rest of the pipeline's state was already on disk.
Replicate it: the blueprint
If the two questions landed in the hours + pass-file quadrant for you, here is the skeleton. Copy, adapt, ship.
project/
.claude/
skills/
strategist/
SKILL.md
writer/
SKILL.md
reviewer/
SKILL.md
drafts/
[yyyy-mm-dd]-[slug]/
brief.md
draft.md
review.md
final.md
.phase/
01-strategy.done
02-write.done
...
rules/
voice.md
structure.md
state/
current.md
Every SKILL.md starts with frontmatter like this:
---
name: writer
description: Writes full drafts from a brief.
argument-hint: [file path to brief.md]
allowed-tools: Read Write WebSearch
---
Body is the prompt. Read these rules. Produce this artifact. Obey these contracts. That is it.
The .phase helper in bash is the ten-line block from earlier in this post: check for a .done marker, run the step, touch .done on success, write .failed on failure. Resume from a crash with ls $slot/.phase/*.done and skip anything that already completed.
The pipeline itself is a shell function that calls phase in order:
run_pipeline() {
local slot="$1"
phase 01 strategy "$slot" claude-skill strategist "$slot" || return 1
phase 02 research "$slot" claude-skill topic-researcher "$slot" || return 1
phase 03 hook "$slot" claude-skill hook-smith "$slot" || return 1
phase 04 write "$slot" claude-skill writer "$slot" || return 1
phase 05 fact-check "$slot" claude-skill fact-checker "$slot" || return 1
phase 06 seo "$slot" claude-skill seo "$slot" || return 1
phase 07 review "$slot" claude-skill reviewer "$slot" || return 1
phase 08 finalize "$slot" finalize_slot "$slot" || return 1
}
Replace claude-skill <name> <slot> with whatever you call each agent (Claude Code SDK, cursor agent, a curl to an API, a local script, anything that reads the slot directory and writes a file). The orchestration contract is: each specialist reads from $slot/, writes to $slot/, exits 0 on success. That is the entire interface.
When this loses
The failure cases are real. Here are the four I would hand to anyone considering the pattern.
Real-time multi-user applications. If ten users are hitting the same agent simultaneously and the agent needs to merge their state, a filesystem is the wrong answer. Concurrency control at the file level is painful. Use a database.
Agents that genuinely negotiate. If your design calls for a debate loop, a jury vote, a critic that argues back until consensus, the filesystem cannot model that. AutoGen's SelectorGroupChat was built for exactly that shape. Use it.
Tight fan-out and fan-in with conditional joins. If you need to spawn twelve parallel workers, each returning a chunk of analysis, and a conditional join that merges only the chunks that passed a threshold, that is a graph. LangGraph solves it well.
Teams larger than three. Every artifact becomes a merge-conflict surface. Git can mediate, but at some point an actual workflow tool (Temporal, Airflow, Prefect) is cheaper than coordinating over a shared folder.
If any of those describe your problem, install the framework that fits. None of this advice applies.
Receipts and what to read next
One source for the biggest number in this post: Anthropic engineering, "Code execution with MCP," November 4 2025. They document token usage dropping from 150,000 tokens to 2,000 tokens when agents load tool definitions on-demand from the filesystem instead of preloading the entire MCP registry. That is a 98.7% reduction, cited verbatim. The mechanism is the same as what I am describing here: durable artifacts on disk, loaded into the model's context only when a specific task needs them. Full post at anthropic.com/engineering/code-execution-with-mcp.
The rest of the receipts are repo-local. Agency start: 2026-04-13. Day five since launch as of the Monday this publishes. Agent roster: 38 at the end of week one, 50 in the week that followed. Cadence: 4 blog, 6 IG carousels, 3 reels, 5 LinkedIn, 14 X threads per week. No framework upgraded along the way. Nothing to upgrade.
If you want the narrative origin of this pipeline (how the agency came together from zero, and what broke the first week), the prior post is I built an agent content agency. For a one-carousel version of the architecture pattern, the Instagram post that accompanies this piece on 2026-04-20 covers the decision matrix in nine slides. For the filesystem pattern itself, you already have it. It is the folder you already made.
Before you pip install langgraph, try a folder. Two markdown files, a naming convention, and git is a lot of runtime for free. The day you need a framework, you will know: the state will start changing in milliseconds, or the agents will start arguing. Until then, the filesystem is the runtime.



